With all the discussion about what the “big trick” is that makes the M1 seem to be such a breakthrough, I can’t help but wonder, if the M1 is more like the iPhone: The sum of a large number of small engineering improvements, coupled with a lot of component integration detail work, topped off by some very shrewd supply chain arrangements.
Analogous to the iPhone being foreshadowed by the iPod without most experts believing Apple could make a mobile phone from that, the M1 was foreshadowed by the A1 for mobile devices with many(most?) experts not forecasting how much it could be the base for laptops and desktops.
It seems, the M1 includes numerous small engineering advances and the near term lockup of the top of the line fab in the supply chain also reminds me of how Apple had secured exclusivity for some key leading edge iPhone parts (was it the screens?).
So the M1 strikes me as the result of something that Apple has the ability to pull off from time to time.
And that is rather hard to pull off financially, organizationally and culturally. And it more than makes up for some pretty spectacular tactical mis-steps (I’m looking at you, puck mouse, cube mac, butterfly keyboard).
> The sum of a large number of small engineering improvements, coupled with a lot of component integration detail work, topped off by some very shrewd supply chain arrangements.
I think the vertical integration they have is a major advantage too.
I used to work at arm on CPUs. One thing I worked on was memory prefetching which is critical to performance. When designing a prefetcher you can do a better job if you have some understanding or guarantees as to the behaviour of the wider memory system (better yet if you can add prefetching specific functionality to it). The issue I faced is the partners (Samsung, Qualcomm etc) are the ones implementing the SoC and hence controlling the wider memory system. They don't give you detailed specs of how that works, nor is there an method where you can discuss with them appropriate ways to build things to enable better prefetching performance. You end up building something that's hopefully adaptable for multiple scenarios and no one ever gets a chance to do some decent end to end performance tuning. I'm either working with a model of what the memory system might be and Qualcomm/Samsung etc engineers are working with the CPU as a black box trying to tune their side of things to work better. Were we all under one roof I suspect we could easily have got more out of it.
You also get requirements based upon targets to hit for some specific IP, rather than requirements around the final product, e.g. silicon area. Generally arm will be keen to keep area increase low or improve performance / area ratio without any huge shocks on overall area. If you're apple you just care about the final end user experience and the potential profit margin. You can run the numbers and realise you can go big on silicon area and get where you want to be. With a multi-company/vendor chain each link is trying to optimise for some number they control, even if that overal has a negative impact on the final product.
Very interesting comment. I mean you see some of the same things with companies like Tesla also pushing vertical integration.
A lot of the examples you see are similar to what you talk about. You can cut down on the friction between different parts.
I remember an example of software controlling a blinking icon on the dashboard, where this was a 10 minute code change for Tesla but a 2-3 month update cycle for a traditional automaker due to the dashboard hardware coming from a supplier.
If we're comparing the M1 to x86, though, then all the prefetching and other memory shenanigans are on the CPU die. The A1 had an advantage over the SoCs used in Android phones here, but the M1 doesn't have an advantage over Intel and AMD CPUs.
> the partners (Samsung, Qualcomm etc) are the ones implementing the SoC and hence controlling the wider memory system.
And I assume the partners also do some things differently, for at least somewhat legitimate reasons, and no one ARM design can be optimal for everyone.
You use the word partner with the proper noun Qualcomm but there are no quotes. Qualcomm's only focus is to make money while delivering the worst experience in every direction. They are often stuck in local maximums and they are too big to just flow around.
Apple has used exclusive access to advanced hardware as a differentiator several times. With screens it was Retina. They funded the development and actually owned the manufacturing equipment and leased it to the manufacturing subcontractors.
Also in 2008 they secured exclusive access to a then new laser cutting technology that they used to etch detail cuts in the unibody enclosures of their MacBooks, and then iPads. This enables them to mill and then precision cut the device bodies out of single blocks of Aluminium.
They’ve also frequently bought small companies to secure exclusive use of their specialist tech, like Anobit for their flash memory controllers, Primesense for the face mapping tech in FaceID, and there are many more. For Apple simply having the best isn’t enough, they want to be the only people with the best.
Retina is a very interesting example for how Apple works. They have identified the necessary resolution (200+ ppi) for this technology and worked towards across their whole product range. The technology isn't exclusive to Apple, but they are the only company which pushes it, even if it sometimes means quite odd display resolutions.
Other manufacturers seem to be completely oblivious to it. They still equip their laptops either with full hd or 4k screens. The resulting ppi are all over the place. Sometimes way to low (bad quality) or way to high (4k in an 13" laptop, halves the runtime). Same with standalone screens, there is a good selection around 100ppi, but for "high res" the manufacturers just offer 4k in whatever size, so once again the ppi are all over the place again.
Retina is a great example of how Apple operates in general. They care about outcomes, not spec sheets. Sure, they'll take the time to spec dunk when the opportunity presents itself. It's just rarely the reason they do something, whereas Dell/HP/whatever want to say "4K SCREEN OMG" on the box regardless of whether that actually leads to a better experience.
Apple realizes there's diminishing returns in upping the resolution beyond what your eyes can see. So they hit Retina, and then move on to focus on color accuracy, brightness, and contrast.
They do this throughout their product stack. Only as much RAM as their phones actually need, because RAM is both costly in terms of BOM and also consumes battery life.
Using fewer Megapixels than competing phones because it's about the quality, not quantity, when other manufacturers trip over themselves to have the most Megapixels.
> Using fewer Megapixels than competing phones because it's about the quality, not quantity, when other manufacturers trip over themselves to have the most Megapixels.
When your customers are picking a product based off a spec sheet, that's the trap you easily fall into.
> Apple realizes there's diminishing returns in upping the resolution beyond what your eyes can see. So they hit Retina, and then move on to focus on color accuracy, brightness, and contrast.
It's still not enough resolution for x2 upscaling that Apple argues optimal.
> The technology isn't exclusive to Apple, but they are the only company which pushes it, even if it sometimes means quite odd display resolutions.
Apple's focus and commitment can be a pain to users who want something different, but overall it's a huge strategic advantage.
Software developers are building their apps for M1 because they know beyond a shadow of a doubt that Apple isn't going to keep Intel around any longer than they have to, whereas Microsoft had and will continue to have a hard time persuading anyone to adopt ARM Windows because the opposite is true.
That would imply split-brain development. Yes I agree that devs will support M1 out of necessity in supporting a minority market share OS that will expand from M1's apparent superiority....
But Wintel will own business desktops for probably a decade, unfortunately.
There are a few PC manufacturers offering 3K laptops at least (Lenovo, Huawei when I looked). For monitors it’s nuts, just Iiyama has a 5k screen with multiple inputs (the LG has only one input so useless for switching between pc and Mac)
Perhaps I'm lucky, but my LG 5K has aged really well. Fantastic upgrade in 2016 and still going strong. I'm surprised there aren't more 5K 27" monitors because they are great.
Personally, I hope Dell makes their own screen with the panel of the 6k Apple display. I would probably grab it in a heartbeat. I would consider the Apple display, but I don't need the reference video quality and especially I would like to have more than one input on a display that expensive.
Apple, what are you thinking? People who can afford that display might want to connect their desktop mac and their laptop to it.
I believe this is the only consumer 5nm chip currently available as well. Ryzen gen 3 is still on 7nm. I'd be interested to see how well general purpose compute on the m1 vs ryzen gen 3 mobile will be.
The thing is M1 performance isn't really the point in itself though. This is the lowest performance core architecture Apple will ever produce for MacOS, aimed at their lowest end cheapest hardware. It's only one data point towards what we can expect when they take the gloves off and go after the performance end of the market for real.
Universal binaries. Apple calls those binaries “Universal binaries”. Rosetta is more like running different arch binaries through qemu. A brief look through Google says that there was a FatELF specification created years back, but never really went anywhere. Presumably because Linux users tend to know what arch they are using.
Fat binaries would make distribution easier, but would double (or triple) the size of a binary. I doubt it would be worth the size trade off.
I’m thinking of all of the small utilities and small command line programs that make up a stock Linux distro. Those don’t have many resources other than the binaries. Sure, the size of each is not much in absolute scale, but combined, you have a pretty significant increase if they were all fat binaries.
That said, I don’t know what Apple does. For example, in the main download for Big Sur, is (for example) zsh a universal binary, or are there a specific x86/M1 downloads. I haven’t looked.
Looking at /usr/bin, /usr/lib/ etc. it's not quite as big as I expected. Going fat might be feasible, especially considering how large storage is at this point.
The Huawei Mate 40 came out two months ago, and uses the Hisilicon Kirin 9000, which is also on TSMC's 5nm. It has about 30% more transistors and a higher clockspeed than the A14.
They're not 'the only ones' in that childish playground bragging kind of sense. If you want one you can buy one from them. It's just business.
Also much of this tech only existed when it did due to their investment in technology development and tooling. Microsoft had dragged their feet on Hi-DPI for years before Apple jumped ahead with retina and 5K and forced them to pull their socks up. Android phones probably went to 64-bit two years earlier than they otherwise would have. With Surface devices Microsoft has come up with some genuinely innovative and forward looking designs and engineering, but would they have done that without the spur of competing with the iPad and Mac? Apple have been single handedly dragging the rest of the industry kicking and screaming into the future, to everyone's benefit. How is that outcome 'evil'?
I think it starts, at least, with simple practicality. Apple products usually sell in massive volumes. When they introduce some new aspect, they have to be able to produce huge numbers of this thing, and since it's new, the industrial capacity to produce at those numbers reliably does not exist. They have no choice but to buy out and invest in all the available capacity, because they rarely release innovations in some small-scale experimental product. They swing for the fences for a mass market home run almost every time.
And they do this so well because they're led by Tim Cook who approaches the big picture in part in terms of supply chain.
I don't argue that cornering the market isn't an accounted-for and desirable side-benefit of this arrangement. I just don't think it's usually the starting point for them.
It’s business. This is all part of the reputation and image Apple wants. Any reasonably managed business will lean into its differentiations. This happens in every business sector at any measurable scale.
Greed sure, but it's also control. Apple has always been fanatical about controlling what the user, seller, repair shops, retail, etc can do with their products. Among other reasons, its one of the top reasons I'll never use Apple computers. I want complete control of my devices, and the ability to break my machines while pushing boundaries. Apple would rather have me locked in to their 30% fee App Store cash cow with apps that require their approval to exist.
I have heard that it might be possible to hack your Mac laptop (using a setting in System Preferences>Security&Privacy>General) to allow it to run code on that isn't from Apple's App Store.
There is no lock preventing you installing non-Apple executable. Theres a warning and such but I install apps from third parties all the time. There are even several package managers, macports and homebrew, that will install userland unix binaries for you.
Brand marketing. It cements the Apple brand as being high quality and Apple products as being better than anything else available, justifying a premium price in the minds of their customers.
It's usually a legitimate justification, too. Nobody else makes hardware this nice, almost as a general rule.
It is not greed, it is ego. Apple as a whole has an ego complex and it shows in so much of what they do. They always, to the point of harping, emphasize the Pro label and premium experience and premium materials. Even their head quarters is an expression of pure ego.
So when compared to other companies which do put out products with similar materials the difference is that Apple never reaches low. They won't sacrifice their premium material usage and expression to reach lower end markets.
Air Pods Max might be the situation backfiring on them. They were so wrapped up in having aluminum enclosures for the headphones they ended up with an overweight and overpriced to many product. It is going to be real curious what a lower cost version of these entail; the rumor is they will come but when and of what materials?
The sum of a large number of small engineering improvements, coupled with a lot of component integration detail work, topped off by some very shrewd supply chain arrangements.
I think you precisely have it. There is no single magic reason the M1 is so good, just a lot of things coming together. They start with a better instruction set than x86, have of course the best process available, and perhaps the largest part, they have built up an increadible team over a decade. And they are extremely focussed in what they target. If anything, that is Apples "magic". They are not making a chip which is built in an abstract manner to be sold to random customers. They have exactly their needs in mind and execute towards those.
In a sense AMD did that with the chips for the Playstation/XBox. Like the M1 it is basically a SOC. There optimized for great graphics performance. Unfortunately, those chips are not sold separately for building your own PC.
So the M1 strikes me as the result of something that Apple has the ability to pull off from time to time.
Perhaps you haven't been paying attention?
Apple shipped 64-bit ARM processors for the iPhone at least a year before Qualcomm could do it for Android devices. The reaction to the A7 was similar to what we're seeing now with the M1—not possible, there's some trickery going on, etc.
Apple is pretty good at this processor transition thing, going from 68k to PowerPC to Intel to ARM.
And it more than makes up for some pretty spectacular tactical mis-steps (I’m looking at you, puck mouse, cube mac, butterfly keyboard).
Except for the recent keyboard issues, you're literally talking about another era. I wouldn't put the shape of the mouse for the 1998 iMac in the same category as transitioning a $9 billion revenue product line to a radically different processor architecture.
> Apple shipped 64-bit ARM processors for the iPhone at least a year before Qualcomm could do it for Android devices. The reaction to the A7 was similar to what we're seeing now with the M1—not possible, there's some trickery going on, etc.
That is because it is not possible to ship a top-end design for a new ISA in that amount of time. The more reasonable answer is they had been working on a new core design for some years before. AMD has hinted that their Zen design makes it relatively easy to swap the x86 frontend for an ARM frontend.
Apple was considering buying MIPS around that time. I suspect they strong-armed ARM into accepting their ARMv8 proposal because it was good and because Apple buying MIPS would be disastrous for ARM's share price. At that point, it wasn't faster than possible, it was just designing the last part of the chip (or if both frontends were being worked on in tandem, cancelling one of them and focusing everyone on the other).
This explains why ARM announced v8 and then took the full 4 years to ship their first low-power core (A53) and even longer to ship their bad first try at a high-performance core (A57 -- with the more baked A72 being superior in almost every way).
> the near term lockup of the top of the line fab in the supply chain also reminds me of how Apple had secured exclusivity for some key leading edge iPhone parts (was it the screens?).
Yes, Apple managed to lock up most of the global supply of capacitive touchscreens for about a year after the iPhone came out. The iPhone wasn't the first phone to use a capacitive touchscreen, but for a while, it seemed like it was because nobody else could produce devices with them in large volumes.
People used to dismiss Tim Cook as "just" a supply chain guy. But I think it's become clear that supply chain management is at least as important to Apple's success as anything on the design or marketing side.
In some ways it is the environment the M1 was born from that helped. mobile space CPU's focus upon low power usage and that has seen many core software tasks get dedicated instructions and why you end up with the M1 in some tests utterly trouncing competition as it has dedicated hardware catering for the common niche things that software ends up doing - the hardware video encoding being a small area, but deep down, more than that. This along with advances in software/hardware integration and being able to synergies that at a level nobody else can. The way to think of it is - if Intel did an operating system from scratch, it would tap the CPU extremely well compared to others due to them knowing the internals better and fully. Then add the ability for them to see that adding some dedicated hardware to replace some software instruction combinations and you start to see a tightly integrated team of CPU and Operating system/software.
One area that I've always wished CPU's would take would be a dedicated core or two for the OS that is completely isolated from the other cores, which would be for the software/applications you run. Now if those ran about two different architectures - darn that would be the inner geek in me appeased.
What would your goal be? I think locking a modern, general-purpose OS to a small number of cores would artificially constrain performance, assuming a reasonable scheduler.
The OS don't need that much grunt, some drivers maybe - hence one or two cores, isolated away from user software and secure.
Scheduler wise it would become easier as no juggling cycles upon main core that the OS is running upon. Whilst not hitting real-time OS levels, it would be a nice middle ground in some area's as well.
Also for cores, the OS and user software don't need the same OS when the OS is just API calls passing parameters, so would be viable to have the OS upon one core type and the user-space cores a totally different architecture. That again would add another level of security.
You can already do this. There's a kernel boot parameter called isocpu or something and the kernel will only run on the logical cpus listed. Furthermore, you can isolate your user programs. The general benefit is latency, but there's a theoretical trade-off in scheduling bandwidth. The memory heirarchy will be utilized less efficiently too.
> The sum of a large number of small engineering improvements, coupled with a lot of component integration detail work,
Exactly. ARM has been progressing faster than Intel. For the past 8 years or so, Apple has had the fastest ARM CPU out there on the iPhone/ iPad. Apple has sucked up TSMC's 5nm production. They've integrated a pile of relevant coprocessors into the CPU and put fast RAM on the package. The SSD is lightning fast and SSD encryption is done via a dedicated coprocessor.
It's not one magic trick, it is countless bits of engineering, manufacturing, and purchase choices.
> by the iPod without most experts believing Apple could make a mobile phone
Except for all the people practically begging Apple to make a phone for years, except all the analysts who wrote essays on how computer companies could make successful phones, except for all the fanboys making fan-art of phones with that big circular wheel.
I don't buy it. I think there is in fact one "trick," which is shedding the X86 decode bottleneck.
People always make the point that the X86 decoder is only ~5% of the die. Sure, that's true, but keep two things in mind:
(1) While it's only 5% of the die, it runs constantly at full utilization. The ALU is also only a small percentage of the die (5-10%). How hot does your CPU get when you're running the ALU full blast? Now consider that there is a roughly ALU-sized piece always running full blast no matter what the CPU is doing because X86 instructions are so complex to decode. Not only does this give X86 a higher power use "floor," but it means there's always more heat being dissipated. This extra heat limits thermal throttling and thus sustained clock speed unless you have really good cooling, which is why the super high performance X86 chips need beefy heatsinks or water cooling.
(2) It apparently takes exponentially more silicon to decode X86 instructions with parallelism beyond 4 instructions at once. This limits instruction level parallelism unless you're willing to add heat dissipation and power, which is a show stopper for phones and laptops and undesirable even for servers and desktops.
People make the point that ARM64 (and even RISC-V) are not really "RISC" in the classic "reduced" sense as they have a lot of instructions, but that's not really relevant. The complexity in X86 decoding does not come from the number of instructions or even the number of legacy modes and instructions but from the variable length of these instructions and the complexity of determining that length during pipelined decode.
M1 leverages the ARM64 instruction set's relative decode simplicity to do 8X parallel decode and keep a really deep reorder buffer full, permitting a lot of reordering and instruction level parallelism for a very low cost in power and complexity. That's a huge win. Moreover there is nothing stopping them from going to 12X, 16X, 24X, and so on if it's profitable to do so.
The second big win is probably weaker memory ordering requirements in multiprocessor ARM, which allows more reordering.
There are other wins in M1 like shared memory between CPU, GPU, and I/O, but those are smaller wins compared to the big decoder win.
So yes this does foreshadow the rise of RISC-V as RISC-V also has a simple-to-decode instruction set. It would be much easier to "pull an M1" with RISC-V than with X86. Apple could have gone RISC-V, but they already had a huge investment in ARM64 due to the iPhone and iPad.
X86 isn't quite on its death bed, but it's been delivered a fatal prognosis. It'll be around for a long long time due to legacy demand but it won't be where the action is.
>This extra heat limits thermal throttling and thus sustained clock speed unless you have really good cooling, which is why the super high performance X86 chips need beefy heatsinks or water cooling.
The 16 core Ryzen has the same TDP as the 8 core Ryzen. Increasing the clock
speed for slightly more single core performance is an intentional design decision, not an engineering flaw. Clock up those Apple chips and they are going to guzzle more power than AMD's chips. https://images.anandtech.com/doci/14892/a12-fvcurve_575px.pn...
Apple's preference for manufacturing processes that optimize for mobile low ower consumption below the 4Ghz range mean scaling up is harder than just slapping a higher TDP on the chips. Remember the TDP of the whole package already exceeds the TDP of the most power hungry Ryzen core running at 4.8Ghz. Apple has enough headroom to boost to the same frequencies but they don't, because of the manufacturing process they have chosen which loses all of its efficiency beyond 4Ghz.
I haven't studied it carefully, but it sure looks like 90% of the performance improvement is using a big cache, which is a totally obvious thing to do. Also the big x86 guys have more or less been asleep at the wheel for almost a decade.
My go to example: my 2011 x220 sandybridge stinkpad is faster than my 2017 kaby lake mbp. 2005 machines (I dunno, Lakeport?) aren't even in the same ballpark as modern machines. Had that pace continued up to current year, the M1 chip would be a stinker. As it is, AMD is close and could smoke M1 in next generation 5nm chips, restoring order to the universe.
> I haven't studied it carefully, but it sure looks like 90% of the performance improvement is using a big cache, which is a totally obvious thing to do. Also the big x86 guys have more or less been asleep at the wheel for almost a decade.
Dude, has Intel called you yet? You've got some serious CTO chops.
AMD has a public roadmap, and (assuming they execute) their next CPU in 2021 will be 5nm.
Apple do not of course, but TSMC have stated they expect 3nm to be produced in volume in 2H22 which tells us we have at least one more round of Apple Silicon on 5nm.
In 2021 we will presumably see Apple Silicon parts with increased core counts and desktop TDP
This will be our first chance to see how the best of ARM goes against the best of X86 in like-for-like configurations.
I think the narrative around instruction set is a bit overblown. I was a chip architect for the shader core at a major GPU company. I worked on simulators and modeling performance for next generation chips where we changed the ISA for each family of chips. The big reason why Apple Silicon is so damn fast is because they were able to shape the design at modeling time exclusively around Mac system level workloads. At best, Intel would have some subset of traces come from Apple for important traces to optimize for. Combine getting to narrow traces down exclusively for one platform, and heterogeneous design space (cpu + coprocessors) and you can really tune a monster.
> The big reason why Apple Silicon is so damn fast is because they were able to shape the design at modeling time exclusively around Mac system level workloads
Is that really the case? My understanding was that M1 is fast because it's able to keep the chip saturated with instructions due to a large L1 cache and wide instruction decoders. Is anything about that specific to mac workloads?
> Is anything about that specific to mac workloads?
The memory and instruction architecture may be more 'generic' but it and the neural engine, storage and media controllers, image processor etc will have been shaped and fine tuned by the requirements of the mac.
It is probably the marginal gains of each subsystem being 5-10% better for purpose that gives it the edge.
Does optimizing for a single system really improve performance significantly in general purpose computing benchmarks like SPEC? IIRC, the M1 also does fairly well with virtualized Linux.
It does. The point is how Apple could use so much silicon space for the CPU in the SoC. Most AP and CPUs are designed to be general purpose as possible, so there are some spaces used for unnecessary interfaces. But Apple could use those spaces for CPU. Also Apple could increase the die size without thinking about profit in chip production because they earn money from their devices, so by selling SoCs like others.
No other companies can do silicon business like Apple.
That doesn’t sound reasonable to my (electrical engineer but 15 years since last involvement in processor design) ears.
Intel has enough product lines that there are no “unnecessary interfaces”; what were the unnecessary interfaces in the Intel chip used by Apple?
Similarly, so does Qualcomm and the tens of other of ARM licensees - any mass market design can find or customize a core with no meaningful dead weight.
It may be a contributing factor, but I have not seen anything to indicate it’s very important.
I give the “many small things done right” theory much higher likelihood - just as in the case if the iPhone, there wasn’t any specific thing that wasn’t done before - except
for a winning combination.
"But Apple has the neural accelerators which are a waste of transistors for most workloads"
Based on?
Many Apple frameworks tie into those accelerators; including frameworks like Metal that one wouldn't necessarily expect.
Another strength of Apple - as a programmer your workloads can gain automatic acceleration as frameworks are extended to leverage new hardware. Note this isn't anything new; it's been going on for years already.
I assume the parent means UNIXy tools which target ARM broadly are still very fast on Apple Silicon. Not to mention VM performance.
But your point, that there's still a lot of Apple stuff at play there, is a fair one. It will be very interesting to see how (native) Linux runs once that porting effort gets more under way...
being "a chip architect for the shader core at a major GPU company" sounds like a dream job for me.
Do you have any interesting tips or books to read for a fellow hardware design engineer? :)
I don't see how an ISA doesn't matter. While not a chip architect like you, I do work as a developer and I know that the interface you make to something affects what kind of performance you can build in the backend.
In principle whether you are using Python or C++ doesn't matter. It is just an interface. The compiler or interpreter in the back decides the actual performance. Yet it is pretty obvious that the specifications of C++ syntax makes it much easier to create a high performance compiler than the specification for Python.
I have been quite involved with Julia. It is a dynamic language like Python, but specific language syntax choices has made it possible to create a JIT that rivals Fortran and C in performance.
Likewise we have seen from Nvidia slides when the went with e.g. RISC-V over ARM, that the simple and smaller instruction-set of RISC-V allowed them to make much cores consuming much smaller silicon, better fitting their silicon budget.
When you worked as a chip architect didn't the ISA affect in any way how hard or easy it would be for you to make an optimization/improvement in silicon?
I mean if one ISA requires memory writes to happen in order, or have variable length, or left too little space for encoding register targets etc. All that kind of stuff is going to make your job as a chip architect harder isn't it?
Also I don't quite get your argument about modeling the M1 around Mac workloads. We know the M1 is having great performance on Geekbench and other benchmarks which have not been specifically designed for Mac workloads.
Only things I can see with M1 which is specific to Mac is:
1) They do the code needed for automatic reference counting faster. Big deal on Mac since more software is Objective-C or Swift which uses automatic reference counting.
2) They prioritized faster single cores over multiple cores. Hence optimizing more for a desktop type workload than a server workload.
3) A number of coprocessors/accelerators for tasks popular on Macs such as image processing and video encoding. But that is orthogonal to the design of the Firestorm cores.
I don't claim to know this remotely as well as you. I am just trying to reason based on what you said and what I know. Would be interested in hearing your thoughts/response. Thanks.
Yes but that is all included in an ISA. A CPU ISA specifies opcodes as well as semantics. Together that affects what optimizations you can do. Or rather how much silicon and brain power you need to accomplish it.
Does this potentially mean that as the OS evolves, the chip will likely become less efficient, as it becomes "out of tune"? Apple could mitigate this obviously.
Not clear what RISC-V has to do with the Apple M1.
Also not clear what benefit RISC-V would have for "coprocessors". GPUs and various machine learning speedup devices are massively parallel devices, intended to run small, specialized programs in parallel on multiple specialized execution units.
Also note that the real win of the Apple M1 is lower power consumption. In terms of basic compute speed, there are Intel products that are roughly comparable. But they use more much more power. This is more about battery life than compute power. (Also heat. Apple laptops have had a long-standing problem with running too hot, from having too much electronics in a thin fanless enclosure. The M1 gets them past that.)
The hardware video decoder is probably to make it possible to play movies with most of the rest of the machine in a sleep mode. The CPU is probably fast enough to do the decode in software, but would use more power than the video decoder.
> Also not clear what benefit RISC-V would have for "coprocessors".
As the article states, the architects of RISC-V recognized that co-processors that assist the CPU to do more and more specialised repetitive tasks will be the norm. Thus, RISC-V was designed in a way to accommodate such co-processors, with limited instruction sets that make its CPU design simpler.
The Apple ARM processor is also similar - the ARM system-on-chip they have designed is highly customised with many co-processors all optimised for the macos / ios platform.
Apple's SoC contains a GPU, an image processing unit, a digital signal processing unit, Neural processing unit, video encoder / decoder, a "secure enclave" for encryption / decryption and unified memory (RAM integrated) etc. (Note that this is not a unique innovation - many ARM SoCs like these already exist in different variations. In fact, it's what made ARM popular.) Obviously, when a system software or application uses these specific units of an SoC to process specific data, they may be faster than a processor that doesn't have these units. And Intel and AMD processors currently don't have these specific units integrated with their CPU.
Anyway, the point the article is making that the RISC-V architects recognized that such co-processors will be the norm in the future, and thus the author is predicting that RISC-V will become more popular, now that the M1 acts a showpiece for the architectural idea the RISC-V wants to popularise.
And this is just idle speculation and I (and I guess Animats) don't necessarily buy. I think RISC-V is doing fine and will grow regardless.
Where more Arm mainstream success will have a slipstream effect on RISC-V is in app porting. There are significant differences between x86 and Arm, notably memory model (AS does support TSO with a flag, but native apps use the weak mode). Porting from x86 to Arm can be non-trivial, whereas porting from Arm to RISC-V is far easier.
As mentioned in the article Nvidia has selected RISC-V to use in their graphics cards after careful evaluation of alternatives. RISC-V beat all the alternatives. A lot of other accelerator card makers are reaching the same conclusions. You can google and find many white papers detailing how RISC-V is getting incorporated into accelerators/coprocessors with great success.
I'm aware of this (I've been doing since RISC-V before it was public), but it seems unlikely to me, knowing how these companies operate, that Apple would use RISC-V for anything when they already have extensive HW and SW Arm64 IP, expertise, and infrastructure.
NVIDIA's use of RISC-V is for the internal power sequencing cores and similar tasks. This is not going into the shaders, nor is Arm64. Their future use of RISC-V for stuff like this will probably continue, but it seems unlikely that they will ever release anything with a user-visible ISA based on RISC-V.
RISC-V is just an ISA. How exactly can it popularize the already extremely popular idea of shoving a bunch of peripherals onto a SoC?
> RISC-V was designed in a way to accommodate such co-processors, with limited instruction sets that make its CPU design simpler
This only affects the extremely tiny embedded space, only under the most extreme constraints you have the "simpler ISA → simpler CPU core design → more space on the silicon for coprocessors" thing.
For a general purpose high performance SoC, you don't want a simple CPU design, you want a fast CPU design, and you have space for all the coprocessors you want anyway.
Other than "being simple", there's nothing an ISA has to do with coprocessors. There's nothing ISA-specific about having memory-mapped peripherals.
Adding custom instructions directly to the CPU ISA instead? That's not exactly coprocessors, that's more like modifying the main processor, it's annoying (fragmentation) and Apple for some reason was allowed to do it with Arm anyway >_<
> Intel and AMD processors currently don't have these specific units integrated with their CPU
Of course they have GPU, video encode/decode, "secure enclave" (fTPM).
Consider tensor cores. They are basically just 4/8-bit SIMD units. Add a very basic integer control unit and some specialized, custom tensor instructions. It's literally just another CPU core from an integration perspective. It shares the same memory/coherency architecture in every way without a bunch of subtle edge cases laying in wait. It even largely shares the same programming model for software making optimizations easier and faster to create in the compiler. Along the same lines, if the OS is aware of the extensions on each core, it can view all processors in the system as "cpu cores", but target specific cores based on their available extensions.
This same process applies to most of the GPU. Nvidia uses RISC-V controllers for this reason. AMD uses a scalar unit of whatever ISA to do one-off calculations and control SIMD flow. A shared privilege model would also be good here. The current GPU landscape is rife with ways to bleed into privileged space. A shared hardware privilege model would go a long way toward dealing with this issue.
> For a general purpose high performance SoC, you don't want a simple CPU design, you want a fast CPU design, and you have space for all the coprocessors you want anyway.
You don't want your one core that does fast CPU execution OR fast tensor OR gpu OR whatever else. You want dedicated cores to do those things AND fast CPU cores too. There are quite a few RISC-V extensions aimed at improving single-thread performance and code density. Like with other ISAs, if there's any low-hanging fruit at the instruction level, it will be added to an extension soon enough.
It could be good to use the same ISA for the coprocessor as for the main CPU, worked well for IBM mainframes.
Smarter Ethernet NICs often contain a CPU to do things like TCP offload, the "microcode" for them can be just machine code for this CPU, having a more open architecture for the peripheral devices would make it easier to add support for more network protocols.
> Of course they have GPU, video encode/decode, "secure enclave" (fTPM).
Yes, they do, but they are limited to that in comparison to the M1. That was my point. The M1 has a lot more co-processors than the current offerings of Intel / AMD.
Hardware accelerator modules also often need their own mini-cpu built in to them as a controller, apart from the main CPU cores. RISC-V was specifically designed for this use case to have a very light weight core ISA, with an extensions mechanism that make it easily customisable for specific accelerator design. Even the lightest weight ARM cores are monsters in comparison.
Thus we are likely to see a lot of new ARM chips containing a few RISC-V cores tucked away inside the design. In fact NVIDIA already does this on some graphics cards and it’s not impossible M1 does as well.
They are both RISC instruction sets used for SOC style chips. So what makes the M1 successful should also work for RISC-V. The key non-technical difference is that you won't have to license it from NVidia which might make it attractive to some companies that don't want to pay as many license fees to these companies.
Licensing and patents have historically been in the hands of only a few companies; which limits other companies doing custom designs. With RISC-V, that could change. Of course that's only the instruction set and you'd likely still need to license lots of patents to get anything shipping. But it fits the pattern of OSS software driving a lot of innovation and hardware design becoming more like software design.
Theoretically, if Intel wanted to make a comeback, RISC-V might actually be interesting for them. Right now they would have to compete with Apple, Nvidia/ARM and the likes of Qualcomm for non X-86 based CPUs. Those three are basically using ARM based designs and you need to license patents and designs to do anything there. Intel having to license chip designs + patents from their competitors is likely not compatible with their ambitions of wanting to dominate that market (like they dominated X86 for nearly half a century). They are clearly having issues keeping X86 relevant. So, RISC-V might provide them an alternative. The question is if they have enough will left to think laterally like that or whether they are just doomed to slowly become less relevant as they milk the X86 architecture.
> Also note that the real win of the Apple M1 is lower power consumption.
Doesn’t this automatically translate into higher performance — by adding more cores or increasing clock rate — since TDP is the limiting factor for CPU speed?
I mean, if someone created a 1W CPU that performed as well as a 100W CPU, would you say “lovely, a lower power CPU” or “overclock/add cores until it reaches 100W and give me that”?
Why do people ascribe broader ARM implications to the M1? Apple uses the ARM instruction set to make an amazing CPU. It could probably make one with the x86 set too. It doesn’t mean everyone else making ARM processors will suddenly get much better. Not to mention that Apple’s very similar A series has already been around for years.
There was an article posted not long ago that suggested the variable length instruction set in x86 chips prevented some of M1's most important design innovations being replicated by Intel and AMD.
It's true that ARM64 has a load-store architecture and fixed-length instructions (the latter depending on the former for encoding space efficiency). Other than that, the instruction set design is very far from minimalist textbook-style RISC ISAs like RISC-V. It has both flag-based branches and fused compare-to-zero-and-branch instructions. It has very complex immediate encodings. It has instructions for loading/storing register pairs. It has pre-increment/post-increment addressing modes of the kind that were hallmarks of CISCs like M68K and VAX.
It seems unwise to draw far-reaching conclusions about RISC-V or even ARM64's intrinsic merits versus Apple's CPU designers when there are so many variables. The frontend decoder hasn't been a frequent bottleneck in Intel cores for a long time and they could scale it up more aggressively if they wanted.
Apple's engineers did a great job. That seems to be the conclusion we can draw based on currently available evidence.
> The frontend decoder hasn't been a frequent bottleneck in Intel cores for a long time and they could scale it up more aggressively if they wanted.
This isn't grounded in any facts. Decoding the variable length x86 ISA costs you exponentially in decoding width, both power and area. You can scale it, but it will never be efficient. The way Intel and AMD combat this is by having a decoded uOP cache from which the issue width is typically twice that of the frontend decoder. Arm64 has an inherent advantage here (RISC-V does not have quite the same advantage as RV64GC instructions are a mix of 16- and 32-bit). Arm64 also is much more recent design than x86_64 that learned a lot from the past experience and isn't bogged down by a lot of useless legacy. This helps.
Arm64 is rather large for a RISC ISA, but it's mostly pretty good (however IMO RISC-V's lack of flags and implementation of conditional branches is superior).
Of course a fixed-length ISA has an inherent advantage for parallel decoding efficiency. The question is whether that is a decisive advantage in M1's impressive performance. After Intel refined their decoder and uop cache, you virtually never see that part of the frontend as a bottleneck when doing microarchitectural profiling. That's been true since Sandy Bridge but even more so since Skylake.
All the legacy junk in x86 is obviously a pain for Intel to support. Any blank-slate ISA is going to have an advantage there.
Presumably the importance of decode bandwidth depends on what you're decoding.
Most classic computationally intensive work (video encoding, science, but also benchmarks) spends its time in fairly tight loops or small kernels, running over large data. uop caches make decode bandwidth irrelevant here.
But general usage of a machine sees the instruction pointer wander all over the place (particularly if you have multiple tabs of JavaScript open). More decode bandwidth means more performance here.
Are compilers are an an example of a heavy workload with a large hot code size? It would be interesting to compare the M1's advantage in compiling to its advantage in, say, video encoding.
It doesn't take exponential power. My understanding is that the basic approach for instructions without boundary tagging in L1I$ is to start decoding every byte in the stream in parallel, discard the ones that don't make sense, and then later propagate boundary to boundary across the length of the fetch window. Sort of similar to how a carry-bypass adder works. This is expensive but not that expensive compared to other structures.
But it does mean that x86 designs tend to carefully balance the size of the decoders to other structures to make sure they're not the binding constraint too often. With ARM the approach seems to be more to make the front end 50% bigger than you think you need to be sure it's never a problem and refill the front end buffers more quickly after a mispredict.
Yeah, the algorithm for parallel decoding you outlined scales linearly in area and power with respect to the speculative look-ahead depth. This is true even if you speculate on more than the per-byte "boundary or not boundary" condition. A parallel-prefix circuit for processing a DFA with m states where you speculate on all m possible initial states for each of n bytes "only" consumes O(m n) power. [1] In absolute terms this is obviously still a problem as you crank up m or n, but the scaling is certainly not exponential. You do see local exponential scaling if the state space is large enough (think of minimax search in chess) but for these decoding problems the state space is tiny and you don't even need to speculate over all possible states (e.g. you're not going to decode all possible combinations of 4 instructions per cycle, only certain prefixes, etc).
[1] The Hillis-Steele paper on data-parallel algorithms from 1986 describes this algorithm for parallel lexing.
You are right it's x^2 not 2^x. However it's bit worse still because the area grows too which either hurts your timing (longer distances) or forces more stages (power, yet more area, and mispredict penalty).
It simply isn't practically scalable much beyond where we are; if it were, you can be sure Intel would have scaled it instead of using µOP caches.
The power scales linearly, not quadratically with the amount of look-ahead. The "m" is the number of states you're speculating on which doesn't grow with look-ahead length. In the case where you're just speculating on whether an instruction starts at a given byte offset, you would have m = 2.
I don't think anyone is saying they could scale up the decoder "for free". If they had a fixed-length ISA, I'm sure they would have increased the decoder width sooner (and using different techniques) since with high-end out-of-order cores you're always looking for cheap ways to over-provision your pipeline even if it only helps on some workloads some of the time. Their current use of the uop cache tells us that they consider it the most economical trade-off at that point in the design space (where the decoder can output up to 4 instructions and the uop cache can output up to 6 instructions); you can't infer that they've hit an impassable brick-wall with instruction decoding.
In any case, it would be relatively simple for intel/amd engineers to evaluate the effect of different parameters using their quantitative analysis tools which include an emulation environment. I don't think it makes much sense to speculate here about these parameters.
The traditional RISC philosophy stemmed from the constraints on chip development that mostly existed from the 80s to the mid 90s. After that ballooning transistor counts and design effort for top line out of order application processors made reducing the number of instructions pretty pointless in that design space, though limiting the number of ways instructions could interact through a load-store architecture and keeping decode simple through fixed length instructions (plus longer jumps) remain relevant useful things to take away from RISC. All the complexities that ARM has let it do more with fewer instructions and a high performance RISC-V core is going to have to do enough instruction fusion that its internal ops will end up being just as complicates as those that ARM uses, but it'll also have the disadvantage of having to do that extra fusion.
But of course if the target isn't a high end application processor but instead a microcontroller, say, RISC-V's simplicity has a lot going for it. Or for a grad student implementing a simple OoO processor in a semester long class. Or back when I was doing my thesis having an open source core to modify would have been a huge advantage. As the article says RISC-V can be a success without replacing ARM, POWER, and x86.
I'm not sure what your point is, but no modern ISA is really bare-bones RISC. They're all somewhere in the middle, including RISC-V, despite the name (it just puts the more complex instructions in optional extensions).
I doubt that --- modern x86 (everything since the original Pentium) breaks instructions into uops anyway and caches those, so if anything I'd say the M1 is impressive despite having relatively large fixed-length instructions.
There's some more discussion in here about the source of the M1's performance, and it largely seems to come down to the smaller process size that enabled Apple to scale up a lot of the structures in the uarch:
> modern x86 (everything since the original Pentium) breaks instructions into uops anyway and caches those, so if anything I'd say the M1 is impressive despite having relatively large fixed-length instructions
I believe this is covered in the medium article that was linked, in part of the discussion on the number of decoders x86 processors have vs the m1. It is in fact this process of breaking instructions into uops that seems to be the bottleneck, and it is apparently not easy to improve this due to the complexities introduced by variable length instructions. If you have reason to think that part of the article is wrong I'm interested in hearing it, I'm not an expert on modern day processor architecture techniques so I don't really have an insider perspective on this issue.
And M1 does the same. All modern CPU's are really similar internally in that sense. ISA is just a frontend that gets translated into micro-ops that then get scheduled based on dependencies and available execution ports. Even the registers in ISA don't match the internal registers at all. ARM64 has 32 general purpose registers in ISA level. M1 seems to have 354 internally [Anandtech]
This is also the reason why the whole CISC and RISC debate in it's original form is outdated. The processors internally are all RISC. But the ISA can be more complex.
The x86 ISA makes the decoder harder to parallelize, so it takes more chip area compared to equivalent width for ARM64. And the wider you want to go the harder it becomes, whereas with ARM64 you just slap more decoders.
Another is the x86 memory model that restricts how stores can be issued into memory so that they're visible to other cores.
This is also a good thing for AMD. They could "just" make a Zen ARM CPU. Sure it would be a lot of work, but vast majority of the chip is shared.
That frontend isn't free and it isn't small. Look at modern Intel processors and you'll see that the decoder takes as much die area as the entire Integer ALU (if you don't count caches). Unlike the ALU which powergates unused ports, the decoder almost never turns off.
The more 1-to-1 your translations to uops are, the less power and die area you need to spend decoding them. In addition, less complex translations means fewer pipeline stages needed for the same design which also has lots of ramifications.
Yap. And ARM has the advantage of requiring a smaller frontend. Especially when one looks at wider decoders.
On the other hand if your ISA is the micro-ops directly then the instructions start to take ridiculous amounts of space. It's a balancing act between instruction size (to save instruction cache) and the complexity of decoding them.
And it's not just about being 1:1. It's also about how wide you can go. And variable length encodings simply are fundamentally more hard to parse in parallel fashion. That means a wider unit is harder to achieve, needing more space and power.
It’s mostly that you can only pull instructions off the queue from the front, whereas with ARM since the size is fixed you can just pull them off anywhere.
I think with x86 Intel and AMD are basically brute forcing this by just pulling instructions off a random position and hoping it’s a correct offset, but it’s very inefficient.
But perhaps Intel/AMD can surprise us with a dynamic allocator that runs in the reorder buffer. Or perhaps they can still push the limit one more time with more transistors. Another option would be to implement a fast-path for small instructions, so in effect they would be moving from CISC to RISC but only for parts of the code that need the extra performance.
Well the perception was that AMD and Intel had a unassailable lead. That even with a power and clock speed disadvantage that the M1 can be quite competitive with several other serious mobile chips, like the Intel I9.
Now apple has proved that a cool running chip that sips power can run a wide variety of intensive applications well.
People were quite dubious of apple's chances on a competitive desktop chip and have just received a wake up call with a relatively conservative M1 chip (3.2 GHz and 4 fast cores).
It wasn't generally thought that amd/intel were unassailable engineering wise, just that sw compatibility, x86 patents and volumes were important enough that it was economically hard to go against them. But other chips (eg IBM) regularly challenged them on speed despite relatively tiny volumes and budgets. And of course years earlier the Itanium debacle + exponentially increasing fab costs (favouring volumes) killed off most of the RISC competition.
Trivia: Simultaneously to the previous Mac ISA transition, Apple acquired PA Semi who had a power efficient and fast PPC chip. Then, Apple decided to go to Intel anyway instead of betting on their new in-house chip. Discarding their newly acquired highly acclaimed chip design, they put the newly acquired semi team to work on the A series of chips instead.
But they had no reason to be skeptical, given the A series. To only take a processor seriously once it’s housed in a case with a keyboard attached is ridiculous.
Well, I kind of agreed with them. It's easy to assume that phone apps written for a few GB ram would not be representative of high end use like compiling large projects, editing 4k video, manipulating large datasets, etc.
But as it turns out the M1 does quite well at quite a few real world aggressive desktop applications.
I was on the other side: Bits are bits, loops are loops. Why there’s a distinction between phone app and desktop app? Isn’t it that the difference is only the UI input method?
At least for the last 5 years an iPhone and a desktop would handle the exact same images, videos, spreadsheets and websites with any desktop and often with better performance.
Why would anyone think that these are fundamentally different?
RAM latency for one thing. Phones have a huge advantage in that area which translates very well to most tasks as long as they have enough memory. OS differences also favor phones in many ways.
No, they don't. Memory latencies for top-end phones like the iPhone are generally over 100 ns, which far from being a huge advantage is consderably worse than the best desktop and latpop x86 chip latencies which hover around 50 ns.
I generally try to quantify TLB latency and DRAM latency separately. The M1 chip has quite impressive memory latency around 30ns, assuming you aren't thrashing the TLB.
Desktops tend to be much higher latency, like say the AMD ryzen 5950X. In particular the R per RV range benchmark uses between 1 and 32 pages in a sliding window. The M1 gets around 30ns (which I've personally verified with code I wrote) and the Ryzen 5950x gets around 65ns. Intel does a bit better than AMD, but nowhere close to the M1.
As we are talking about comparing different CPU architectures it’s the external latency that’s important. Even then I have been looking at sub 25ns on AMD CPU memory benchmarks and I assume similar Intel numbers.
If anything it's made me more interested in micro-PC's. I have been playing a lot with Raspberry Pi's lately, and the M1 shows how much better we could do in that form factor. Why can't I have an Apple Silicon SOC the size of an iPhone, with the battery and screen replaced with a heat sync and a couple of ports?
We do and it's called the mac mini. The actual circuit board looks to be about 2x the size of the pi. Their only reason for the massive mini case is economies of scale. They have to leave that case around for the intel mini for another year or two and all the tooling exists, so they didn't have any costs there either.
I think the real next-gen mini should have been the iPhone 12 pro. Imagine a desk with just an Apple monitor, charger, and wireless keyboard. Pop your mag-safe phone onto the charger so you have a trackpad. The mm-wave connects to the monitor for video and giving access to it's USB-c ports. You get the normal mac desktop ready to start working for the day. It's not as powerful as most desktops, but it can give tons of plugged-in laptops a run for their money. More than good enough for 95% of users.
It’s slightly tangential, but I’m managing an engineering team of 28-30 and we’re currently considering a wholesale change to ARM CPUs across the board.
MacBooks are our de facto development laptop and all our services use skaffold for local development, Docker basically. If we consider the perhaps likely outcome that MacBooks will one day be ARM-only, that Docker will not offer cross-arch emulation, and that our development environment will be ARM only, it then becomes likely that we’ll migrate our UAT and PROD to ARM based instances.
If we go that route it’ll mean more money to the AWS Graviton programme and likely further development of ARM chips. I can’t see this affecting RISC-V but the M1 switch could very well benefit the wider ARM ecosystem.
You’re basically locking yourself to a single development eco system, and a highly limited deployment eco system.
It’s not clear what the benefits of either are either. I get that the MacBook gets great performance for battery life but the majority of work is gonna be done in desktop settings, so simply using more/equally powerful x86 chips is only gonna cost you a few dollars a developer per year in electricity costs.
And all that despite the fact that your development is on Docker which doesn’t even have a working solution for the workflow you’re considering at the moment.
It‘s currently in consideration and by the time we’re ready to make a call on it, Docker will be too. They almost are in fact.
But consider that we may be optimising for different things. Most new developers I hire can be thrown a MacBook and they’ll know what to do, Linux on the other hand doesn’t have that guarantee especially towards the junior and front-end market segments of where I work. It’s a (real) broad strokes opinion, but I’m of the belief that macOS and by extension MacBooks offer us fewer overheads in terms of setup, maintenance, onboarding, tooling suitability for the median developer. So that leaves us using macOS.
This is the factor we’re optimising for more than deployment portability - we optimise for vendor lock-in in less than the developer experience for the median of our developers. For many of us on this forum we may be best with Linux on a bleeding edge distro, but for our preferences we deploy MacBooks for portability. Whether it helps things overall, this is in Manila where a net monthly salary is often less than the cost of a laptop, so we deploy one device that can be transported between home and work as required for those that don’t have a personal device.
With that, I see this as Apple locking us into that ecosystem rather than a choice we’re making on our side, so I’d rather lean into this and explore it further than doing nothing. If it comes out positive then we’ll be ready to make the switch before Apple forces us into it, and if not we’ll deploy something thinkpad-esque and keep our production instances x86.
"With that, I see this as Apple locking us into that ecosystem rather than a choice we’re making on our side, so I’d rather lean into this and explore it further than doing nothing. If it comes out positive then we’ll be ready to make the switch before Apple forces us into it, and if not we’ll deploy something thinkpad-esque and keep our production instances x86."
As a long time Apple user (personally and staff wise), please don't tie your business decisions with company that treats professional users badly, every time they can. Your median developer benefits from Linux knowledge in general, you can deploy stable distribution without fear of compatibility problems after minor software update.
Apple marketing and lure is great, I have fallen for their game for 20 years. But I cannot be comfortable with ideas, business and management practices that this generation of Apple deploys.
They destroyed entire indie businesses by arbitrary changes and/or enforcement of App Store policies, not to mention they're leading the war on general purpose computing as we know it by locking everything down.
I want to be able to tell my children I didn't participate in that.
If I compile the list of all anti professional moves that Apple has made in recent years I will get depressed and I don't like to be depressed:)) Here, watch this funny rant from proven Apple professional user, may be it will give you some insight. https://www.youtube.com/watch?v=MKJjLwMUPJI
On other hand most valuable company in the world uses slave labor and gives the consumer highest possible price, I cannot support this dynamic anymore. https://www.youtube.com/watch?v=zeEERdbfH0c
M1 performance is about much more than just battery life, it’s screaming fast is raw execution power as well. In single core it’s even competitive with Ryzen for goodness sake. That’s just mental.
I don’t see this as a significant lock in risk. It’s not like Apple are the only company selling ARM laptops and desktops, and it seems clear Google, Microsoft and Amazon among others are serious about ARM.
x64 virtual machines, Docker, etc have to be supported on Apple's M chips for a long time to come. There's zero risk of this changing soon unless Apple wants to scuttle the non-iOS/non-Mac developer market for Mac.
M1 is a cool chip, but there's no reason for an average development company to rush into it unless targeting M1 MacOS specifically. Maybe the server world swings to ARM, but that will take decades to sort out, if it actually happens at all.
It took about 10 years for x86 to go to zero marketshare in servers into 80%+ in the 90's. Similar change in HPC market etc. So based on history the transition time is around 10 years, not tens of years.
That would mean 1 out of every million servers is not x64, which seems hyperbolic when amazon is making ARM servers and power chips are still out there.
"Macs are now crazy-fast but they're still Macs so few people will switch".
Anecdotally there have been a bunch of posts on HN since the M1 Macs shipped by people who've either stopped using Macs years ago or who've never bought a Mac previously who are happy M1 Mac owners.
The M1 Mac mini retails at $699, but I've already seen it as low as $625. There's certainly nothing in that price range that's better.
And even before the M1 Macs shipped in November, Mac revenue hit an all-time high of $9 billion in the quarter that ended September 26, 2020 [1]. Apple often highlights that about 50% of Mac customers are new to the Mac, a trend that's likely to accelerate.
The second narrative doesn’t explain AWS throwing its weight behind ARM.
Not to say that ARM is killing x64, it’s definitely not, but ARM is clearly being invested in and rolled out at a massive scale by 2 of the biggest tech companies in the world in both consumer devices and server side. To me that’s quite something.
AWS is throwing their weight behind ARM because they have thousands upon thousands of servers. Their Graviton2 chip runs between 1-1.8W/core [0] and has 64 cores. Their TDP is half that of the EPYC and Xeon equivalents. At data center scale that's a huge savings in power. They could also increase density in the same power envelope.
If Amazon were to move significant amounts of their non-EC2 server hardware to Graviton they can see cost savings with no end-user impact. If an AWS product doesn't run client code there's no real requirement to run it on x86.
I wish the t4g was available in Singapore… I had to settle for t3a, but the cost savings there combined with using spot instances behind a custom load balancing/dynamic scaling setup (nginx+3rd party modules for hot ip reloads+python daemon using cloudwatch free tier stats) deploying from AMI (docker and k8s needed machines that were 2x ram than just using AMI) made server costs at my last company super cheap, and probably saved amazon even more than when we were running on t2.
Apple is playing the margin game not the volume game. Just like Apple takes something like 98% of the profit in the global phone manufacturing business, I wouldn’t be surprised if they’re doing the same thing in the developer compute market.
Worth noting that the ISA is more than a set of instructions it’s also a semantics for those instructions. For example the concurrent semantics of ARM processors permits a much larger array of optimizations on the per thread level which is good for performance.
2) More registers. ARM64 has 32 general purpose registers and 32 registers for SIMD stuff. x86 has fewer registers which are also wasted on all sorts of legacy junk.
3) More lax restrictions on memory-write back. It is easier to optimize the Out-of-Order execution on ARM, as you don't need to write back everything in order to memory.
As for everybody else. ARM designs from ARM Ltd. is showing rapid performance increases and gradually closing the gap to x86. It really is inevitable as there is NOTHING special about the x86 ISA that gives it higher performance. Nothing prevents other ARM makers from catching up: https://medium.com/swlh/is-it-game-over-for-the-x86-isa-and-...
1. They want some level of backward compatibility, and they were on x86 before.
2. Most of the Tools and Library they used are on x86. Not only from MS & Sony, but also Game developers. It is going to take some courage to change all of that.
3. When the design of PS5 and Xbox X started, none of the ARM CPU IP design, ( In fact even as of today and next year, or may be even 2022 ) has a Single Core Performance that rivals AMD's Zen 2, and certainly not Apple's M1.
4. GPU IP, both are from AMD. Which may actually be more important that the CPU IP from a gaming perspective.
5. In case you ask why not Nvidia then since they made ARM SoC like those in Nintendo. Nvidia's pricing for latest Gen IP is way out of touch. Hence that is why you only see non-leading edge tech used in Switch. ( Nvidia is not a player that wants to sacrifice Margin for Market Share, which is actually a fair point )
Nobody is selling high performance ARM chips. Apple isn't selling their chips. ARM from others have been optimized for micro controllers, phones, servers and super computers. Not for high performance desktop system of game consoles.
If you wanted a high performance alternative to x86 in the past, you would have to go with PowerPC, which Playstation famously did with Playstation 3. Except that was a disaster because the architecture was too novel.
That experience made Sony, very afraid of doing anything unconventional hardware wise.
But I supposed Apple may have opened the flood gates and my prediction would be that next generation Playstation will be ARM based.
> Except that was a disaster because the architecture was too novel.
But it had nothing to do with PowerPC instruction set. Xbox 360's CPU used PowerPC instruction set too, but Microsoft went with much more classical 3-core design instead of single core + 8 SPUs that Sony used.
The only impact PowerPC had on game developers was making them aware of load-hit-store performance hit.
It's not even clear that the M1's big leap is due to ARM vs x86 rather than say 5nm vs 7nm (amd) or 14nm (Intel), or design ideas such as big/little cores and more specialized accelerators (which is ironically against the risc idea which people are claiming as the reason why arm vs x86 so the reason m1 does well)
Specialized accelerators doesn't explain it, because we're measuring a lot of general purpose CPU tasks for the most part.
Big/little is good for power consumption, not so much for performance which is still good.
There's a lot of microarchitectural goodness here beyond ARM, though. Apple's got lots of little details right, and fat connection to memory helps, too. It doesn't hurt to be on leading fab, too.
Having dedicated silicon for most frequently used primitives (specialized accelerators) helps in getting those out of the way for the main core's pipeline execution to run predictably fast.
That makes no sense here. For compilation workloads and a lot of these other tests where we're showing benefits, basically any machine is able to give well over 99% of CPU to the task. Just how exactly do you think that having any dedicated silicon is helping clang compile benchmarks, etc?
It's the same "thickness" as desktop (or good laptop) DDR4, i.e. 128 bits. Apple is running a very high clock though, and with other manufacturers, even for laptops with soldered memory they were quite conservative with memory tuning, basically running JEDEC spec. Maybe now they'll feel the kick in the ass and overclock their RAM already.
The top level things like process node, ISA and memory controller are big. But a lot of boils down to being able to shape the entire chip design exclusively around system level traces of real mac workloads. Intel needs to factor so many different kinds of traces into their chip design. Even windows vs apple makes a huge difference.
So your prediction is that the chip will be bad at running Linux and windows?
To me it seems a priori quite unlikely that the patterns of MacOS, windows and Linux are so different that this would be a major win. There may be a few specific things, but any CPU that prioritizes to much for some particular os would have big problems running CPU-intensive user-space-only workloads.
I'm out of my league here but I've seen references to 8 bit cores that can run at a couple of giga instructions a second. It's hard to understate the performance vs power cores like that are cable of. Also sub nanosecond interrupt latency.
Think a small coprocessor with local memory that's pulling commands out of a queue and managing an io controller. Couple of wins, lower power consumption, fewer context switches, and cache pressure.
Originally it was because the US government requires a second source for any components and so Intel had to license it to somebody to supply the US government.
Then later AMD's 64 bit instructions became the standard, so Intel needed the license for the 64 bit extensions and AMD needed the x86 base and so they just decided to cross-license and call it good.
Which lawsuit? The mid-late 2000's one after all this history? Or the 1991 one that was about intel seeking ways to squeeze out AMD from it's license? The first one isn't really relevant to this and the second one could have been more direct but AMD having a license and then getting another later as part of the deal on x86-64 does allude to behind the scenes shenanigans.
There's actually a 3rd x86 license, that has changed hands quite a few times (Cyrix -> National Semiconductor -> Centaur(IDT) -> VIA -> Zhaoxin, I think, unless I missed a few transitions?)
The Pentium patents have expired too, and if we go by the usual 20-year expiry, then that would mean everything up to the Pentium III (1999) would be in the public domain. IANAL.
Isn't the point of patents that instead of ideas being kept secret (and often vanishing when their inventors die) they are published in exchange for a limited time monopoly on their use? In that case when a patent expires it does indeed become public domain.
Sure, Intel didn't have any serious patents on the 8080 but they did copyright the assembly language mnemonics. So the Z80 was 100% compatible at the binary level but had to use other names for the instructions. Same thing with trademarks.
What I was saying is that what is described in the patent text can be freely used after the patent expires.
ARM has been eating away at Intel for a while now, the same way Intel ate away at the mainframe and minicomputer market in the 1980s and the MIPS/Sparc/HPPA/Alpha workstation market in the 1990s. While the mainframes and minis ate the low-cost PCs for lunch in the 1980s, and the $20,000 workstations of the 1990s had far better performance than a 386 (or even 486 did), PCs were cheaper and more widely available.
It was the economies of scale and the standardization on x86_64 that made the PC the performance king in the first 2000s decade. Intel (and, of course, AMD) x86 did not have the best ISA but they, because of economies of scale, had the best fabs which let them outperform anything else.
While Intel was dominating with raw performance in the first 2000s decade, embedded chipsets slowly coalesced around the ARM ISA, a process which was accelerated by Apple choosing ARM for the iPhone (Nokia also used ARM in a lot of their phones).
Moore’s Law finally stopped working for Intel and they stopped being able to outfab everyone else in the mid-to-late 2010s; a 2012 x86 chip has about the same performance as, say, a 2017 x86 chip.
Intel saw the writing on the wall with people using non-Intel ISAs for phones, and tried to make an Atom chip which would work in a phone; it was a flop. Nobody wanted the x86 ISA unless they needed it in systems which ran legacy applications.
With the Raspberry Pi moving up from only suitable for specialized embedded applications to having near-desktop level performance, and with Apple finally making an ARM chip which is competitive (and in some cases superior) to Intel’s desktop chips, and with legacy x86 Windows applications being in many cases replaced with webpage and smart phone applications, it looks the industry as a whole is finally moving past x86 and its bloated instruction set.
This is a much needed breath of fresh air for the computer industry. I like the M1 because I like that we now have mainstream non-x86 desktop/laptop computers again.
I think RISC-V has a lot of potential, and I am interested in what comes of it in the 2020s, whether it blooms like the ARM did, or if it goes the way of the HPPA, Alpha, or Sparc.
> Nobody wanted the x86 ISA unless they needed it in systems which ran legacy applications.
It wasn't fast/efficient enough. If it had been faster or with better power consumption it would've been fine. There was a massive push to get Android studio to automatically compile X86 binaries for you etc.
But why would you put an Atom in your phone if it means it's slower and worse battery life? That's the reason it flopped. ISA change is a hindrance for switching, but it can be overcome. Even if Intel had sold Atom chips with ARM ISA and identical performance to the X86 variant it would have still flopped due to the poor performance and efficiency.
>legacy x86 Windows applications being in many cases replaced with webpage and smart phone applications, it looks the industry as a whole is finally moving past x86 and its bloated instruction set
Similar predictions about lack of importance of legacy support made over the past 40 years have not borne out. Performant x86 emulation is an absolute must for a replacement ISA.
The broader point is that RISC-V provides the freedom and a practical ecosystem in which to innovate. Custom instructions may only be a small part of that.
The PC platform has plenty of freedom for innovation, it's actually quite open, you can create what ever peripheral, addon, whatever you want on top of it.
The problem is that if you want mass adoption of your fancy new bespoke offer it's quite a bit tricker no matter how good it is at doing it's thing, and that problem does not got away with different ISAs, probably harder to be honest.
You cannot innovate in how things are integrated however. You got to stick to the industry standards. Nor can you say innovate by switching the CPU architecture in your computer.
A vertical integrated system like a Mac allows for much more innovation.
In fact this is true for any vertical integrated system. If you look at Amiga, NeXT, SGI, SPARC and many others, they where always far ahead of the PC in terms of technology.
Sure, you can create a closed vertically integrated system which will allow you the freedom to do what you want, but you've not created a platform for others to integrate with when you do.
The point is those industry standards make the PC a more open platform, where multiple vendors can contribute innovation on the same common basis.
I'm missing the reason why RISC-V in particular is (claimed to be) so much better suited for building specialized co-processors. Are they talking about ISA extensions? Or maybe that the royalty free model makes it cheaper?
Maybe you skipped the section "What is the benefit of sticking with Risc-V"?
> But for a coprocessor you don’t want or need this large instruction-set. You want an eco-system of tools that have been built around the idea of a minimal fixed base instruction-set with extensions.
Essentially: the modular nature of Risc-V and tooling/ecosystem built around it, with first class extension support.
ARM is closed, too complex and not friendly to extensions, while custom ISAs mandate a huge amount of extra work.
I only dabble in this field, but I see the ecosystem rapidly maturing. The open nature also leads to a general propensity to open source designs and tooling, lowering the barrier to entry and reducing cost.
I think people think it's going to be a vibrant open ecosystem in collaboration with industry and academia with a lot of development and fresh ideas leading to some significant simplification and so opportunity for performance and functionality breakthroughs. I don't know if that's true or not.
Same, I love the idea of RISC-V but I don’t really get how it’s better either from a technical standpoint. Would love to hear more about the main advantage of RISC-V against others.
I implement RISC-V for a living and for fun. Arm64 is a very good modern ISA. RISC-V is good too. Comparison with RISC-V must account for the much broader purpose of RISC-V, but just to focus on a few points (I'm not an Arm64 expert though):
* RISC-V (RV64GC) have simpler instructions than Arm64. It's possible it would have a slight frequency advantage given the same implementation resources, but Arm64 might need slight fewer instructions. Notably, Arm64 have more addressing modes. Fusion and cracking makes this mostly a wash, but implementing a RV64 cores is a lot easier than an Arm64 (I speculate).
* Arm64 has load pairs and store pairs; this is a significant advantage.
* RISC-V has no flags and conditional branches directly compares operands. This look like a significant advantage in the code I have looked at and is easier to implement (no flag renaming etc.)
A load pair takes one address generation and one slot in the load queue but returns 2 x 64-bit. It doubles your load throughput at the cost of the complications from an instructions that return two results.
Apple's A14 can issues three loads per cycle. Assuming they can all be load pairs (I don't know currently) that would be 6 loads per cycle. This is frighting :)
The story is similar for store pairs, but probably less important as stores are rarely on the critical path.
Hmm, it's hard to say (and a lot depends on how performant you make the vector loads) but it's really not comparable as the load pairs target any arbitrary (and renamed) architectural registers, whereas the vector load targets a different register file and just a single vector (= much more regular).
What exactly makes RISC-V easier to implement? Is it only about fewer instructions? Or is it as much or more about the semantic s and simplicity of the instructions you got to implement?
Is it possibly to point out some important things that increase the complexity noticeably in implementing ARM?
I haven't even attempted to implement AArch64 and only browsed the ISA, but it's all of these things. Instructions are many and some semantics that are more painful, like handling flags which are exactly like mini registers and the load pair/store pair instructions I mentioned. Also, there are more addressing modes which puts pressure on the load path. All this complexity hurts even more when it comes to verification.
RISC-V has a tiny basic instruction-set consisting of very simple instructions. That makes it possible to implement a RISC-V core on a very small silicon die. Smaller simpler cores make it easier to increase clock frequency as well as reduce watt usage. That gives RISC-V an advantage over the competition such as ARM, where any implementation will require a much larger and complex core to handle all the ARM instructions you must implement to be a valid ARM CPU.
It won’t happen. People (aka businesses) want something that just works for the person doing data entry or scheduling calendars and expects the code rguy (even if a top 3 in the world by value by valuation) to suck it up to bare bottom IT policy.
My opinions are my own. But the things one sees coming from them, they make things up to justify their continued existence.
Although I think the premise of the article is wrong, it is nicely written.
A major nitpick: unified memory is being massively over hyped. There is a reason GPUs have their own memory bus -- contention. CPU/GPUs fighting over access to memory causes massive disruption to very parallel computation. Even if Intel/nVidia resolved their fight over inter-CPU connectivity or we're talking POWER and nVidia using NV-LINK, you still need extra memory ports to keep things fed. The more cores and the faster the GPU the more memory bandwidth required.
I expect to see future Mac Pro M1 series machines with multiple CPU sockets -- at which point memory isn't unified any more, and all the regular CC-NUMA tricks will be used. But it won't be a big deal.
> unified memory is being massively over hyped. There is a reason GPUs have their own memory bus -- contention. CPU/GPUs fighting over access to memory causes massive disruption to very parallel computation.
Not sure I totally agree with this.
Game console have unified memory architecture and it’s a beloved feature. It greatly simplifies things and allows the CPU to far more easily use results computed by the GPU with complicated sync commands or frame delays.
Maybe unified architecture is less valuable for non-interactive programs. I’m not sure. This is a fair bit outside of my wheelhouse.
Memory access is definitely one of the biggest bottlenecks. So I fully agree with the general concern. And you may even be right that the unified architecture isn’t that interesting. But I’m not so sure it’s the problem you think it is.
It does indeed make it easier to code. But you may have noticed that Xbox X has moved to having different speed memories with different memory controllers, even if logically contiguous and uniformly accessible. The CPU pool has a narrower bus and can't be used for graphics objects -- you have to queue for copy to the graphics pool. The driver then schedules a deconflicted copy.
The PS5 architecture also has different speeds -- but the slow access is to SSD! It has manual management of streaming resources from SSD to RAM, but also allows direct SSD reads -- but that is a trick, because the SSD controller has a huge RAM cache too.
So I'd say we're actually moving away from UMA in general. I think that memory aware scheduling is going to be the next win -- online learning to understand memory access patterns and scheduling compute and cache fill. Fancy cache algorithms used to take too much logic (and slow cache fill logic down), but for SSD->RAM you can do lots of prediction based on program state.
Apple is super fucking rich, I wouldn't be surprised if they are ready to pay TSMC enormous money to make monster monolithic dies, and Mac Pro could be single-socket only, packing >128 cores into one socket.
You need lots of memory too. Maybe not an issue for the desktop. If they doubled the SOC for 16 cores (8 hot/8 cool) and 32GB of RAM that would be a decent Mac Pro.
But plenty of people want >32GB of memory, I routinely use machines with 256GB. No way you can get enough RAM into the SOC. Large core counts are even harder, because speed of light means you need a new on socket switched architecture, memory on the other side is slow to access etc. TANSTAAFL.
They probably won't use DDR-on-package for Mac Pro tier chips, so RAM could be whatever they want, they could put an 8-channel DDR4 controller onto the SoC, or even DDR5 if they don't rush it to market ASAP.
But it would be cool if someone did a tiered HBM+DDR system already.. (AFAIK Fujitsu A64FX is HBM-only) maybe the Mac Pro could be that. I kinda wish AMD did that though.
I did indeed read that, but it has nothing real to say about it. Instead it says this:
> Apple uses memory which serves both large chunks of data and serves it fast. In computer speak that is called low latency and high throughput. Thus the need to be connected to separate types of memory is removed.
That is just hand waving. It is possible to produce such memory, but it involves ultra wide busses, far wider than optimal for filling CPU caches, and preferably directly connected to the GPU rather than a multi-master bus or switch.
There is the possibility that Apple has built a very fancy memory interposer that leverages the short distances in the SOC to present the memory both wide (to GPU) and narrow (for filling a queue of L2 misses), so that cache fills pause while GPUs read/write. That would be a highly interesting piece of logic. But of course it can't scale outside of the SOC.
Well yeah they are exploiting the fact that they have an SoC. And they don’t need to scale outside the SoC. There is still space to add a lot more memory.
I don't really see the advantage of using RISC-V as the ISA for a specialised processor. Yes you can have some tooling advantages because the basic stuff is done for you but such ISAs are often hyper specialised. You may not want everything in the RV32I/RV64I (the basic RISCV instruction set) and you'll certainly want a whole bunch of stuff that isn't in an existing extension and you may want to do things in a way that's fundamentally incompatible with the existing ISA (maybe you want flags or condition codes, maybe you want a giant register file with indirect addressing, auto increments and weird memory addressing modes, maybe you want variable length instructions or fixed width that's greater than 32 bit etc).
The complexity is in the specialised stuff anyway so having a RISC-V base is unlikely to save you a huge amount of effort.
The author attempts to point to Nvidia as an example
> Because RISC-V has such a small and simple instruction-set it beat all the competition, including ARM. Nvidia found they could make smaller chips by going for RISC-V than for anybody else. They also reduced watt usage to a minimum.
As I understand it Nvidia's use of RISC-V was for controller cores, its not the main ISA doing the important work (i.e. Whatever they use for the shader cores in a GPU). I suspect they chose RISC-V primarily because there were no arm cores that precisely fit their requirements, so RISC-V gives the opportunity for a custom design that does.
So yes RISC-V is great when you have a need for a CPU that doesn't fit nicely with what arm already provides. In a coprocessors these are likely to provide control and coordination. You'll still want to build a custom ISA for the custom accelerator side of it.
> Going for custom proprietary instruction-sets is thus not a good idea
(In reference to why you'd use RISCV for co-processors in general)
I'm arguing the custom ISA is essential to building the co-processor (or at least makes it easier). The fact your application is super specialised means the existing RISC-V software ecosystem doesn't really help you.
Nvidia's use of RISC-V is incidental, not a key part of their GPU architecture.
Isn't that the whole point of RISC-V's ISA extensions system though, so you can use a minimal base of standardised instructions for generic stuff with established developer tooling, but still have custom application specific instructions tuned to your design?
> Instead of spending all that silicon on more CPU cores, perhaps we can add more coprocessors instead?
Isn't it always a trade-off and some balance? You can add more specialized processors (ASICs) but that also takes away space from general purpose processing units on your die. So depending on the workload your co-processors might be useful or simply dead weight that's not utilized but takes away from the general purpose units that could be useful.
Dead weight, maybe, but unpowered dead weight. That’s the real tradeoff here. If you devote all of your silicon to one big general purpose machine, you need to use it for everything and so it’s always powered.
If your general purpose machine can do every task but nothing well then it’s essentially always wasting a lot of energy. A collection of special purpose cores, on the other hand, might power on and off at different times, depending on the need. Each one could perform its task with a great deal of speed and energy efficiency. The whole system would then be much more energy efficient because it would only use the resources it needs to perform its tasks.
It’s like choosing to own either: a) a Ferrari super car or b) a minivan and a super sport bike. In the former case, you can go really fast if you want, but you’re going to be wasting a lot of fuel getting groceries or picking the kids up at school. In the latter case, you have one vehicle for mundane tasks and another for high speed fun. Your fuel costs will be way lower and you’ll be much more energy efficient!
Relatively rarely utilized, but power efficient, ASIC blocks are a natural consequence from the problem of big transistor budgets and diminishing returns of using it on CPU cores, and chips being limited by thermal & power consumption.
If you want a computer with maximum general purpose power, you can buy a Threadripper today. For the rest of us who use laptops, we want energy efficiency without throttling the machine to death. Special purpose cores are a great alternative to heavy throttling of a general purpose machine.
>"For the rest of us who use laptops, we want energy efficiency without throttling the machine to death"
I am not sure about worldwide ratio of "us" vs them. Personally I have desktop and laptop. Laptop is not as powerful as desktop but it is still a little monster soon to be replaced with the big monster of laptop. Laptop is being used for going to client, general development when staying out of the main office for extended time in summer etc. I am not using it in a settings where the external power is not available so I do not really care about the efficiency. Rather I care about performance, especially during builds.
That depends. I'm fine with using Ryzen 9 with 12 cores without the need to go to a Threadripper. I doubt it would work in a laptop well. It does need a good cooler.
For typical desktop workloads you are not going to have much advantage over 8-cores. More cores are very useful for servers, but Apple's primary concern is to demonstrate good performance under desktop workloads.
The 4 high performance cores and 4 low performance cores of the M1 should give more than enough performance for regular desktop tasks, writing emails, browsing, desktop publishing etc.
But as a desktop user you have special use cases where you really need performance. A lot of people who use Macs use them for video editing or image editing. These are demanding tasks and it makes sense that Apple has made special hardware to deal with these tasks. A MacBook Air with M1 e.g. can now encode video at less than half the time of the most expensive high end iMac ($4000). That means that specialized hardware really pays for itself.
General purpose cores are no different than ASICs most to the time, as neither one will be needed for most common workloads. In a regular day to day usage you are never going to need say 32 cores working constantly.
As a software developer I can see a benefit for more cores to do compilations, but most people are not developers and anyway Apple is planning 32-core M chips.
Anyway for the kind of work I do now my 2013 model Mac Pro is still more than fast enough. But I do do video and audio work at times. Here those special coprocessors would really benefit me as well.
My workloads include running VMs and compiling something like Linux kernel so I do benefit from more cores. But I don't want to run a server for such tasks. Desktop CPUs like modern Ryzens work pretty well for it.
Also, single core performance benefits gaming, especially when you run things in Wine where there is more overhead.
Hardware accelerated video encoding is already handled by discreet GPUs, so the benefit of putting that also in a CPU/APU is moot in the desktop use case.
What so far is missing are cards that support AV1 encoding in hardware. I doubt Apple will be much of help here too.
By integrating everything rather than having a discrete GPU, you get performance benefits. With discrete GPU you can have beefer GPUs because you are given a bigger thermal budget. However you also loose performance from having to move data between CPU and GPU over a slow bus.
I doubt integrated GPUs will ever reach the performance of discreet GPUs, as you said - thermal budget is the limiting factor. PCIe speeds are increasing, so that's not a big issue.
If anything, I expect some of these co-processors to become new PCIe connected cards. I.e. in addition to GPU you'll have some other *PU with its own cooling.
Varuous co-processers have been usually hamstrung in development time, stable APIs, SDKs and developer support. They basically never had the issue of chio yield.
Even video transcoding by the GPU and SIMD instructions in CPUs, that have been around for decades, remain poorly supported by most programming languages.
Why do you have to have less general purpose cores? If they're not powered up at the same time they're not competing for power or heat. They're competing for space but does that matter much when you're packaging chiplets?
Not all is bad, the whole aspect of the M1 bringing alternative CPU architectures to the front mindset outside the mobile landscape is good.
Remember ARM been around for years but has lacked in some area's of code development and been a back-seat passenger in so many avenues and drivers being one of those that stands out. Now the push to cope with two architectures more will be more prominent in design of software as well as support.
That all ends up laying the foundations that will only go to help alternative CPU architectures more over the one x86 size fits all that many avenues have and are still based around.
We have been slowly reaching a plateau in CPU performance and been case of adding many cores and riding the process node for that performance leap as more space for more cores at same power limits. That has almost already plateaued and now seeing lower power usage as already have enough cores, start to become more viable for desktop. So many timing factors do start to play out now and RISC V or whatever others are out there will now have a better chance to compete upon a playing field in which their worst case would be good enough for many tasks and their best case would be able to shine and not be held back as unable to scale as easily due to limitations as those limitations eroding away, albeit slowly it is a case that we are slowly by surly seeing things move in the right directions.
As an aside, I'd perversely love a CPU that had multi architecture cores on-board - even if was two CPU's architectures on the same SOC core.
That all said, still waiting for ECC memory to become more mainstream consumer wise.
I don't think things will work out this way at all. The best DSP coprocessors generally use a VLIW instruction set and no amount of extensions will turn RISC-V into that. The best graphics coprocessors use a SIMT instruction set and no extension will make RISC-V into that. The best media decoding and encryption corpocessors use a fixed function pipieline without any instructions at all and so there's no way they could have one ISA or another.
In software you can have very low development cost by using existing open source tools hidden behind nice abstraction layers. Hardware design doesn't have such nice abstraction layers and while IP blocks exist designing one has a certain irreducable cost which won't be reduced that much by using a RISC-V design. But the performance penalties of trying to use a general purpose ISA, even one with extensions, are very real and won't be enough to make the savings worthwhile.
> The best DSP coprocessors generally use a VLIW instruction set and no amount of extensions will turn RISC-V into that.
Please check P extension.
> The best graphics coprocessors use a SIMT instruction set and no extension will make RISC-V into that.
Please check V extension.
> Hardware design doesn't have such nice abstraction layers and while IP blocks exist designing one has a certain irreducable cost which won't be reduced that much by using a RISC-V design.
RISC-V is still in its early stage, but all these concerns have been considered seriously. The foundation hosts many different Task Group to tackle all possible needs.
> But the performance penalties of trying to use a general purpose ISA, even one with extensions, are very real and won't be enough to make the savings worthwhile.
That doesn't seem to have anything to do with software scheduled general parallel execution of instructions. Letting you have a branch, an arithmetic operation, and a load in the same instruction for example.
> Please check V extension
SIMD is not the same as SIMT. SIMT doesn't handle divergent flow control well compared to a general purpose computer. However it does do it better than SIMD, even predicated SIMD, in important ways.
I think that trying to come up with one ISA that can handle every use case is liable to be just as successful as coming up with one programming language that can handle every use case.
RVV has facilities specifically for handling divergent and convergent SIMT control flow. RVV is an excellent target for code in languages such as CUDA and OpenCL. Yunsup Lee's PhD thesis shows how (using a direct predecessor of RVV).
It's an interesting argument. From a software perspective it's like building in a standard interpreter (eg lua) and extending it with a library that talks to your application. So you get the benefit of a standard interpreter (lua or RISC-V ISA) that you can use standard tooling on, plus the appropriate extension for your use-case.
Important to note that this board is basically a developer kit for adapting software or implementing drivers, not something intended for actual users. It's way too expensive/underpowered for that.
Actual end user desktop/laptop/phone SoCs are probably years away (apart from specialised cores).
I'd very much love to eventually have something like a Risc-V edition PineBook and PinePhone though.
It's hard to tell at this point, but it should be close to or even overall better than Pi 4 / Pi 400 performance -- worse CPU (but better than Pi 3+), but better and more RAM and better I/O e.g. M.2 SSD. And whatever real GPU you want to put on it instead of the fairly low end one on the Pi 4 -- SiFive are demonstrating their board with the Radeon RX580, a 150W $300 GPU but lower end ones should work fine too.
All at a much higher price than a Pi, of course, but similar to x86 PCs.
Compared to x86 PCs the CPU performance is probably around 2001 or so Pentium III or PPC G4 but, again, with everything else (16 GB DDR4 RAM, M.2 SD, GPU of your choice) current generation.
>Featuring an 8-wide decode block, Apple’s Firestorm is by far the current widest commercialized design in the industry. IBM’s upcoming P10 Core in the POWER10 is the only other official design that’s expected to come to market with such a wide decoder design
Other contemporary designs such as AMD’s Zen(1 through 3) and Intel’s µarch’s, x86 CPUs today still only feature a 4-wide decoder designs (Intel is 1+4)
A very deep reorder buffer:
>A +-630 deep ROB is an immensely huge out-of-order window for Apple’s new core, as it vastly outclasses any other design in the industry. Intel’s Sunny Cove and Willow Cove cores are the second-most “deep” OOO designs out there with a 352 ROB structure, while AMD’s newest Zen3 core makes due with 256 entries, and recent Arm designs such as the Cortex-X1 feature a 224 structure.
Exactly how and why Apple is able to achieve such a grossly disproportionate design compared to all other designers in the industry isn’t exactly clear, but it appears to be a key characteristic of Apple’s design philosophy and method to achieve high ILP (Instruction level-parallelism).
A huge number of execution units:
>On the Integer side, whose in-flight instructions and renaming physical register file capacity we estimate at around 354 entries, we find at least 7 execution ports for actual arithmetic operations. These include 4 simple ALUs capable of ADD instructions, 2 complex units which feature also MUL (multiply) capabilities, and what appears to be a dedicated integer division unit. The core is able to handle 2 branches per cycle, which I think is enabled by also one or two dedicated branch forwarding ports
On the floating point and vector execution side of things, the new Firestorm cores are actually more impressive as they a 33% increase in capabilities, enabled by Apple’s addition of a fourth execution pipeline. The FP rename registers here seem to land at 384 entries, which is again comparatively massive. The four 128-bit NEON pipelines thus on paper match the current throughput capabilities of desktop cores from AMD and Intel, albeit with smaller vectors.
Massive low latency Level 1 caches:
>128KB L1 Data cache for which we can test for, however following Darwin kernel source dumps Apple has confirmed that it’s actually a massive 192KB instruction cache. That’s absolutely enormous and is 3x larger than the competing Arm designs, and 6x larger than current x86 designs
The huge caches also appear to be extremely fast – the L1D lands in at a 3-cycle load-use latency. AMD has a 32KB 4-cycle cache, whilst Intel’s latest Sunny Cove saw a regression to 5 cycles when they grew the size to 48KB.
Massive L2 Cache:
>On the L2 side of things, Apple has been employing an 12MB structure that’s shared between their four big cores. This is an extremely unusual cache hierarchy and contrasts to everybody else’s use of an intermediary sized private L2 combined with a larger slower L3. Apple here disregards the norms, and chooses a large and fast L2.
In comparison Zen 3 has 512 KiB L2 per core, and Tiger Lake has 1.25 MiB L2 per core.
Another point tweeted by the author of the above piece but not in the above article...
Much more accurate branch prediction:
>Finally doing perf counters on a dedicated test bench... 9900K having 60% worse branch misprediction than Apple's A12.
I do wonder if part of Apple's success might just be from accepting a lower clock speed. By allowing more FO4s of wire and gate delay between clock latches you can get more done and have to accept as many compromises in dividing your logic up, say 24 FO4s instead of the standard 16. Less timing overhead lost to the latches and clock jitter. And less pain and energy lost around distributing the clock signal in the first place. You'll never be able to clock as high as more highly pipelined designs but if you beat them through parallelism while using less power that's the design point you need in a mobile processor. You're losing some performance/transistor efficiency in your cores but those are a minority of your wafer size.
> There's more going on with the M1 design than "it's ARM/RISC".
Yeah, but the interesting part is how many of these points are enabled by the 64-bit ARM ISA.
> Featuring an 8-wide decode block, [...] x86 CPUs today still only feature a 4-wide decoder designs (Intel is 1+4)
This is the obvious one: 64-bit ARM has fixed size instructions, so you don't need to know the size of each instruction to decode the next one, making it much easier to parallelize. But there's a less obvious detail, shown by that "1+" on the Intel design: for microcoded instructions which can generate many µops, only one of the decoders can be used. AFAIK, no instructions in 64-bit ARM can generate that many µops, probably at most two µops per instruction (for the load and store pair instructions), so probably all decoders can be used for all instructions. This is an advantage (and in fact the whole point) of a RISC design.
> A +-630 deep ROB is an immensely huge out-of-order window for Apple’s new core, as it vastly outclasses any other design in the industry. [...] we estimate at around 354 entries [...] The FP rename registers here seem to land at 384 entries, which is again comparatively massive. [...]
My guess is that these are all consequences of the 8-wide decode: they had to increase all these resources, otherwise there would be a bottleneck. The reason Intel and AMD don't have as much would be because their bottleneck is elsewhere, so it would be wasteful.
> 128KB L1 Data cache for which we can test for, [...] a massive 192KB instruction cache [...] The huge caches also appear to be extremely fast – the L1D lands in at a 3-cycle load-use latency. AMD has a 32KB 4-cycle cache, [...]
It's quite curious that the L1D is four times the size of the AMD L1D cache, while AFAIK the page size used by iOS and macOS (16KiB) is four times the page size used by Intel and AMD (4KiB). My guess is that the L1D size could be increased without getting slower precisely because of the page size increase; the L1 cache is usually VIPT, which has lower latency because it doesn't have to wait for the TLB, but has the disadvantage that you can get cache aliases unless only the bits which do not change in the virtual to physical translation are used to index the cache. So to increase the L1D cache, Intel and AMD have to increase the number of ways, which is already at a massive 8 ways for a 32KiB cache (and increasing it has a latency cost); increasing the page size allows you to increase the cache size without increasing the number of ways. And 64-bit ARM can go even further; its standard page sizes are 4KiB, 16KiB, and 64KiB, the later being the default for at least RHEL/CentOS, so we might soon be seeing even larger L1D caches in ARM servers (this last page size is also required for huge amounts of physical memory, which is probably why RedHat chose to use it).
And for the instruction cache, we again have an advantage of the ARM ISA: for legacy reasons, whenever data is written to memory in the x86 architecture, the instruction cache has to either be written to, or the corresponding instruction cache line has to be implicitly invalidated. ARM doesn't have that legacy: all instruction cache invalidation is explicit. This means that aliases in the instruction cache are much less of an issue on ARM (in the worst case, they are just duplicating information in the cache), which allows the L1 instruction cache to be much bigger without increasing the number of ways.
> This is an extremely unusual cache hierarchy and contrasts to everybody else’s use of an intermediary sized private L2 combined with a larger slower L3.
I don't have an opinion on why Apple used that L2 cache design; it might be because, with the larger L1 caches, there's less need and/or advantage of having a "closer" (less latency) L2.
Putting a CPU core in your hardware accelerator seems more useful when it's stuck on the wrong side of a memory bottleneck. That way, you could run longer programs in local accelerator memory before you have to take the hit of communicating with the rest of the system.
Apple's M1 seems designed to give all types of cores equally fast access to the same memory pool. At that point, it might make more sense to make your accelerator cores as simple as possible and program them from the CPU.
I guess what's really not clear to me is why, if you're building your main CPU on ARM, you would pick RISC-V for your programmable accelerators in the same SoC, rather than using one of the smaller ARM cores available.
It is mentioned in the article. ARM has a much larger and complex instruction set which means you need to have a larger silicon real-estate. E.g. for a minimal core with similar features, cache etc, a RISC-V CPU would take half the die space of ARM. Half the size is 4x cheaper, as cost grows exponentially with die area.
Looking at press releases from various customers of Andes and SiFive, it seems that a minimal 2-stage RV32E is about half the size of Cortex-M0+ (which has a very crippled instruction set compared to other 32 bit ARMs), and 3-stage RV32IMC is 1/3 the size and power consumption of Cortex M3.
Using 64 bit RISC-V instead of 32 bit doesn't double the size, as the instruction decode and control logic don't change, so 64 bit RISC-V is smaller than 32 bit ARM.
64 bit ARM is of course a totally different ISA to 32 bit ARM, and is massively complex with hundreds and hundreds of required instructions -- you can't subset it. FPU is compulsory. NEON SIMD is compulsory.
I don't even know what the size and energy use comparison is between minimal 64 bit RISC-V and minimal 64 bit ARM. 10x? 20x? It's got to be something like that.
I'm also curious whether they're vulnerable to spectre (any variant)
I seriously doubt it—that was nearly 3 years ago.
According to an Ars Technica article, ARM dealt with the issue far better than Intel or AMD [1]:
"ARM's response was the gold standard. Lots of technical detail in a whitepaper, but ARM chose to let that stand alone, without the misleading PR of Intel or the vague imprecision of AMD.
For the array bounds attack, ARM is introducing a new instruction that provides a speculation barrier; similar to Intel's serializing instructions, the new ARM instruction should be inserted between the test of array bounds and the array access itself. ARM even provides sample code to show this."
Every superscalar processor in the past several decades is vulnerable to some Spectre variant. The Apple A1s were also susceptible to one of the Meltdown variants, not sure if that one is fixed in the M1.
It is a question of relative advantage. RISC-V has in relative terms much stronger benefit used in co-processors than ARM. That will drive RISC-V adoption in this area.
However for general CPUs the RISC-V is not as obvious, although we have seen some early claims of some really efficient RISC-V implementation with much higher clock frequency than ARM at lower watt usage. So sure, when we no more, it may turn out that RISC-V is also the superior choice for main CPU. But at the moment, that is more of an unknown.
If we for the moment only assume a slight advantage to RISC-V over ARM, then ARM will stay ahead of the game, because it is already entrenched. People have lots of tooling and software for ARM. You don't switch to a whole new CPU architecture without clear benefit.
But there is an interesting argument/speculation to be made about what happens in the wider PC industry in response to M1. By the time PC makers start getting serious to meet the challenge from M1, it may have become apparent that higher performance RISC-V are possible. Thus it could possibly encourage Apple competitors to attempt to leapfrog Apple by going towards RISC-V instead as main CPU.
But nothing happens without Microsoft, so who knows. A lot of coordination needs to happen.
>If we for the moment only assume a slight advantage to RISC-V over ARM, then ARM will stay ahead of the game, because it is already entrenched.
Licensing costs and NVIDIA's ARM purchase --hostile company with plenty of lawsuits with current ARM licensees-- will offset the (non-existant beyond Apple and a few Windows netbook experiments) entrenchment ARM has on the desktop.
>People have lots of tooling and software for ARM. You don't switch to a whole new CPU architecture without clear benefit.
There's been a lot of effort put into tooling for RISC-V over the last few years, with more ongoing. The RISC-V foundation member list is not to be ignored. There's strong corporate and government backing behind RISC-V.
The existing licenses won't disappear, but whether new cores and/or new ISA revisions from ARM will get licensees post-NVIDIA purchase is anybody's guess. Mid/Long term, I just don't see ARM stand a chance against RISC-V.
It will be interesting to see, but both macOS and Windows already run on ARM and it is a widely known instruction-set. For companies to suddenly switch to RISC-V instead I think there needs to be some very clear advantages.
I am starting to see hints that RISC-V designs may be able to outperform ARM by a good margin. But thus far I don't think that is a firmly established truth.
The main blockers are B and V extensions not being ratified yet.
They're close to ready and some chips are being released that support the drafts, but as these extensions are required for high performance implementations and as incompatible changes might still happen, these chips aren't going anywhere but embedded, where there's control over the whole stack.
And SBC devboards, where people will grab them with full awareness of this situation. Besides SiFive, there's the PicoRio, some new SBC SoC from Allwinner, and a successor for the kendryte k210. All meant to be purchasable in early 2021. Some of them with these draft extensions. Meantime, I am playing with FPGAs (iCE40 and ECP5).
All of that will of course be resolved in the next 12 or 24 months.
Too late for Apple, at least in this iteration. Once they have completed the AS switch they could contemplate another one in maybe five years, if there's some advantage. Even in two years, before developers build too many arm64 assumptions into their freshly-ported from x86 code.
The RISC-V has a terrible Instruction-per-Clock and thats where Arm shines over x86. The idea that's specialty hardware is an Apple invention and that you cant get that with x86, is also ludicrous. Take a x86 CPU from AMD or Intel and add a RTX 3090 and you have specialized hardware for ML, graphics, ray-tracing and video encoding/decoding that runs circles around an M1.
I think you’re fundamentally misunderstanding what the article is saying.
The article literally gives several examples of co-processors for x86 going right back to the original 8086 and 8087. Where you get the idea it’s saying Apple invented the concept is kind of confusing.
Also it’s not about RISC-V versus ARM. It’s about ARM chips containing RISC-V cores as local controllers inside the accelerator hardware, and why that makes sense.
RISC-V is designed to be super simple to implement, this means simple instructions that do one thing, like add or multiply. In a more complex design you have add and multiply, but also add-multiply that does both. By having that more complex instruction you can get more work done on a single instruction, but it requires more silicon.
If your goal is: build a CPU that is as simple as possible, with as few gates as possible then RISC-V is great, But if you are trying to get good performance, then RISC-v is a bad design. I think RISC-V is great, and i think it will se a lot of sucsess, because there are many applications for a slow, simple and free CPU, but it wont compete with x86 and ARM on performance.
I don't think you quite appreciate how clever RISC-V has been designed. RISC-V is very well designed to be used with both complex and simple micro-architectures. By combining instruction compression and macro and micro-fusion you get everything you claim only x86 and ARM can do an more. Here is a proper explanation of how:
How many architectures bother with a non-SIMD multiply and accumulate? I don't think it's a big issue to be missing the single form. RISC-V's vector instructions have it.
Sure, if your goal is to get the longest running battery then you want something else, but this is also the problem with Apples design, it is designed to be low power.
If you want the best graphics/ML/Compute/Ray-tracing/videoencoding/decoding and you are not running on a battery then the M1 is not for you. I think this is a big deal, because it will mean that all the innovation on the bleeding edge will happen on other platforms then the MAC.
In WIN/Linux land loads of people are innovating, on hardware for all these things, OS features, applications, peripherals (Like VR). On the Mac side almost nothing can happen unless one company makes it happen. A single company have limited resources and most of all attention span.
The problem with controlling everything and doing everything yourself, is that you have to be the best at everything. In the long run you will fail at something. My guess is that the GPU is where Apple will fall behind first, and where it will be most obvious. They simply dont have the muscle and inclination to go head to head with nVidia on GPUs.
The whole impressive thing about the M1 is that it is low power AND fast. With all other current gen processor you can only pick one.
> They simply dont have the muscle and inclination to go head to head with nVidia on GPUs.
I wouldn’t bet on this, Apple has a history of barging into markets and becoming tech leaders in them. Mainly because they have enough money and clout to attract the best talent in the areas.
No the have a terrible history of catering to high-end needs, b2b and specialty needs.
Remember the Xserver? They killed off most of the high end video market with FinalCutX, Everyone in the CGI space will not forgive Apple for what they did to Shake. The drop of OpenGL made loads of CAD apps give up on Apple. AAA game developers have long ago given up on Apple making something competitive. And add to that the debacle that was the trashcan, and the cheese grater. Neither of which was anywhere near competitive.
Apple is great at figuring out what the mass market wants, for everyone else they have a very poor track record.
I agree that on the software front it’s a whole different story.
I was thinking about broader categories like the music players (initially derided), phones (that Ballmer interview really aged poorly and and all large phone manufacturers couldn’t believe what was happening). Watches - all the media portrayed the Apple Watch as a failure even years after it was a market leader. The M1 is the same story, all the benchmarks were showing that A series chips had great performance compared to x86 and yet people still somehow managed to be surprised that M1 is fast.
That’s why I wouldn’t bet agains apple when it comes to graphics cards. Now, the software story is different. Even if they have the greatest GC, the question is “what for?” As you mentioned they managed to scared off professionals. And they chased gaming away years ago.
That's taking it a bit too far. Now that Apple has shown multiple times that software can be used to bridge the transition from one architecture to another, I have a feeling that x86 will also take a similar route of revisiting the ISA to scale up the performance while supporting legacy ISA through software.
What is this goddamn obsession with trying to make RISCV anything and everything? It's a very mediocre instruction set architecture that is used because it's, and this is the most important part, royalty free, and this also helps, there is lots of free enthusiastic labor that builds support for it into bintools, gcc and so on so you get a working toolchain without spending coin.
Check at 51:30 where he says "Are there any ARM snipers? No .. I would Google RISC-V and find out all about it. They've done a fine instruction set, a fine job [...] it's the state of the art now for 32-bit general purpose instruction sets. And it's got the 16-bit compressed stuff. So, yeah, learning about that, you're learning from the best."
RISC-V has learned a lot from the mistakes of previous ISAs and made sure the instruction-set fits both low power consumption solution as well as high performance solutions.
All sorts of benchmark tests show that RISC-V from a theoretical standpoint would execute programs faster. You can tell this by analysis how how many instructions are needed for different programs for different architectures.
And how many clock cycles are needed per instruction etc.
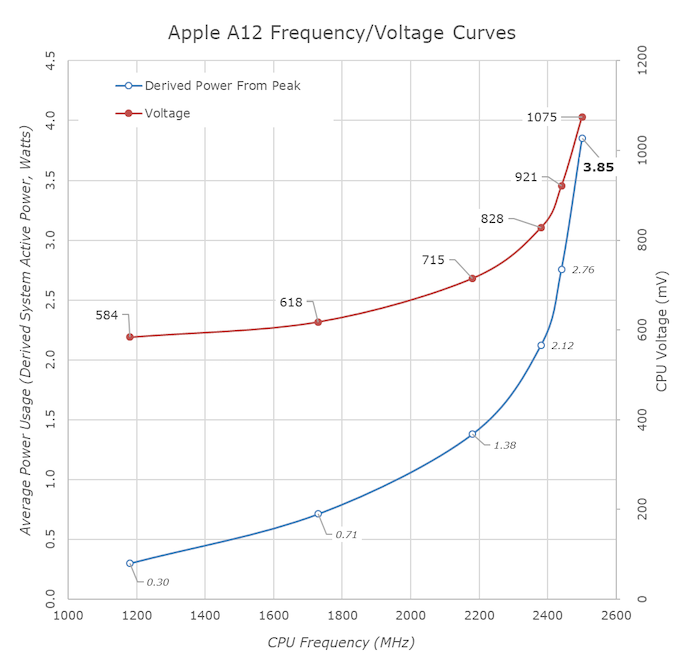{kind=link}
{kind=link}
Analogous to the iPhone being foreshadowed by the iPod without most experts believing Apple could make a mobile phone from that, the M1 was foreshadowed by the A1 for mobile devices with many(most?) experts not forecasting how much it could be the base for laptops and desktops.
It seems, the M1 includes numerous small engineering advances and the near term lockup of the top of the line fab in the supply chain also reminds me of how Apple had secured exclusivity for some key leading edge iPhone parts (was it the screens?).
So the M1 strikes me as the result of something that Apple has the ability to pull off from time to time.
And that is rather hard to pull off financially, organizationally and culturally. And it more than makes up for some pretty spectacular tactical mis-steps (I’m looking at you, puck mouse, cube mac, butterfly keyboard).
EDIT for typo